
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- Transformers
- BELU
- MT-DNN
- Conversation System
- boj
- Chatbot
- scaled dot-product attention
- BoostCamp
- multi-head attention
- layer normalization
- KLUE-RE
- NLP
- 백준
- GPT-1
- Transformer
- Dialogue System
- Prompt Tuning with Rules for Text Classification
- KLUE
- fine-tuning
- beam search
- BLEU Score
- 취업
- Relation Extraction
- ai-tech
- bert
- FSML
- huggingface
- Eliza
- text classification
- pytorch
Archives
- Today
- Total
dukim's blog
[WK02-Day008][21.08.11.Wed] CNN 본문
Intro
- 이고잉님 특강: git & github
강의 내용 복습
Convolution
- 네트워크 발전 방향
- parameter 수를 줄이는 방향
- 앞단의 CNN을 깊게, 뒷단의 FC는 최소화
- 커널 사이즈를 줄이고 깊게 쌓음 : 보다 적은 parameter로 동일한 면적의 receptive field를 커버 가능
- 1 x 1 convolution : dimension reduction(channel), 깊게 쌓으면서 parameter 숫자를 줄일 수 있게함, bottleneck architecture(e.g. ResNet )
Modern CNN
Key takeaways
- VGG
- parameter 수를 width & height 에서 줄임
- 동일한 면적의 receptive filed를 커버하면서 parameter 수를 줄이기 위해 커널 사이즈를 줄이고 깊게 쌓는 방식을 제안
- GoogLeNet
- parameter 수를 channel 에서 줄임
- 1 x 1 convolution을 사용해 channel dim을 reduction
- ResNet
- skip connection으로 네트워크를 깊게 쌓을 수 있게 함
- DenseNet
- ResNet에서 skip connection시에 sum 대신 concatenation을 활용
- 1 x 1 convolution을 적절히 활용해 커지는 차원을 조절
CV Applications
- Semantic Segmentation과 Detection이 어떤 문제이고 초창기에 어떤 방법론들이 있었는지 소개
- 보다 심화된 방법론은 뒤에서 소개함
Semantic Segmentation
- 이미지의 모든 픽셀이 어떤 Label에 속하는지 분류
- Dense classification, Per-Pixel classification이라고 부르기도 함
- 자율주행 분야에 활용
Fully Convolutional Networks(FCN)

- 일반적인 CNN은 마지막 텐서를 flatten하여 FC 레이어에 입력
- convolutionalization : 이 과정을 convolution 연산처럼 변환
- parameter의 개수는 좌 우 동일하다.
- 이 과정을 통해 각각의 픽셀마다의 output을 heatmap처럼 표현가능하게 됨
- input spatial size에 상관없이 네트워크가 돌아감
 ))
))
(출처: Fully Convolutional Networks for Semantic Segmentation) - 다만 spatial dimension이 줄어든다는 한계점이 있음(coarse output, resoultion이 떨어진 output)
- 그래서 이를 다시 원래 사이즈로 복원해줘야함(->deconv, unpooling)
Deconvolution(conv transpose)
- spatial dimension을 키워주는 연산(엄밀한 역연산은 아님)
- 아래는 2 x 2를 5 x 5로 deconvolution하는 예시
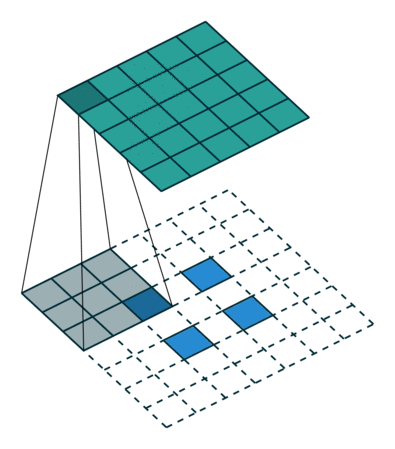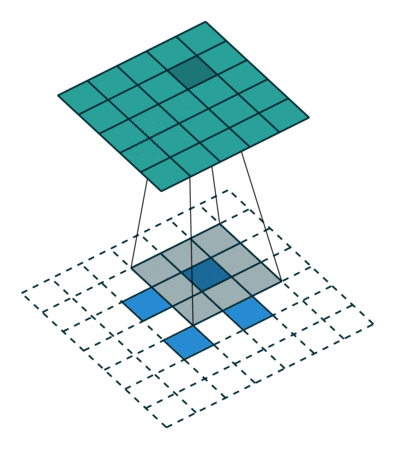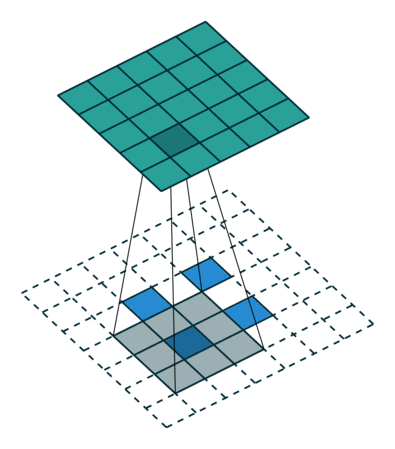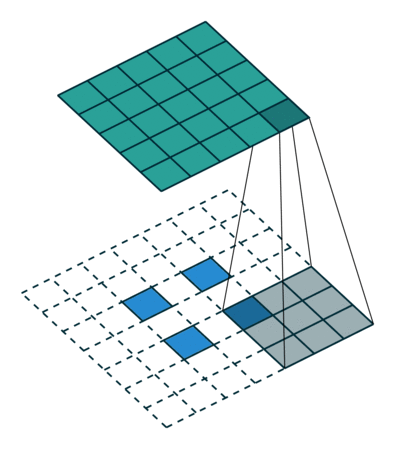 ))
))
(출처: https://github.com/vdumoulin/)
Detection
- 앞의 task와 비슷하나 per-pixel이 아닌 bounding box를 찾아 분류하는 문제
- bounding box를 찾는 방법
- bounding box와 class probability를 같이 찾아가는 발전 흐름
R-CNN
- 초창기 방법
- 이미지에서 selective serach 알고리즘으로 2천개의 region을 뽑아냄
- 각각의 이미지를 CNN(AlexNet)을 이용해 feature를 뽑고
- SVMs로 분류
- 한계: 각각의 이미지마다 2천번을 CNN 및 분류 연산(약 1분)
- bounding box regression에 대한 내용도 있으나 생략
SPPNet
- 하나의 이미지에 대해 CNN을 한 번만 돌리자
- bounding box는 뽑아두고
- 이미지의 CNN을 한 번만 수행해 얻은 feature map의 텐서를 각각의 bounding box에 해당하는 fetch만 뜯어오자
- spatial pyramid pooling: 뜯어온 각 부분을 활용해 하나의 fixed dimension vector로 바꿔주는 것과 관련된 방법. 여기선 생략
- R-CNN에 비해 빠른 연산
Fast R-CNN
- SPPNet과 컨셉은 비슷하지만 뒷단에 Neural Network(RoI feature vector)를 통해서 bounding box regression과 classification 했다는 점이 다름
Faster R-CNN
- Region Proposal도 학습을 하자
- Faster R-CNN = Region Proposal Network + Fast R-CNN
- Selective Search는 Detection에 맞지 않음. 임의의 방식에서 동작하는 bounding box를 뽑아내는 알고리즘
- Region Proposal은 해당 위치에 물체의 유무만을 탐지
- Anchor boxes: 미리 정해놓은 bounding box의 크기
- FCN 활용, 해당 영역에 물체가 있을지를 판정
- 각 pixel마다 54=9*(4 + 2)개의 차원의 vector로 출력됨
- 9: anchor box type, 9개의 미리 정의된 region sizes 중 하나로 분류
- 4: bounding box regression, 4개의 (width, height, x, y) 값에 대한 regression parameter
- 2: bounding box classification, 해당 box를 사용할지 여부
- 좀 더 다양한 물체를 fine-grained 하게 잡아낼 수 있음
YOLO(v1)
다른 detection algorithm에 비해 매우 빠른 속도
- baseline: 45 fps / smaller ver: 155fps
빠른 이유: bounding box와 class probabilities를 동시에 예측한다(bounding box sampling step이 따로 분리되어있지 않음)
절차

(출처:You Only Look Once:Unified, Real-Time Object Detection- 이미지를 S x S grid로 분할
- 이미지 내에 찾고 싶은 물체의 중앙이 해당 그리드에 들어가면, 그 그리드 셀이 해당 물체에 대한 bounding box와 그것이 무엇인지를 같이 예측해줘야함.
- 각 셀은 B(=5)개의 bounding box를 예측
- pre-defined size 없이 그냥 5개의 boudning box의
- box refinement(x, y, w, h)
- confidence (해당 박스에 물체가 존재하는지 여부)
- 2의 과정과 동시에 각각의 셀은 해당 셀에 속하는 객체가 C개 class 중 어떤 class에 해당하는지를 예측. 원래라면 bouding box를 찾고 각각을 예측하는 과정을 여기선 동시에 수행
- 위 두 정보를 취합하면 박스와 이 박스가 어느 클래스인지 나오는 것 (S x S x (B * 5 + C) 형태의 출력)
- 이미지를 S x S grid로 분할
과제수행
- 강의에서 진행하는대로 따라하면 되는 내용이므로 생략
피어세션
오늘의 모더레이터 : 추창한
발표 : 최한준, 이호영
최한준 :
- 수업 : (04강) Convolution은 무엇인가? 복습
- 알고리즘 : DFS / BFS 알고리즘
추창한, 한진님의 질문
이호영 :
- 이전에 진행했던 Kaggle 프로젝트 설명 및 소개.
- 월마트 판매 데이터를 이용한 프로젝트
추창한
- 이전에 진행했던 도서 추천 프로젝트 설명 및 소개.
학습회고
- CNN에 대해 교양강의 듣듯이 편하게 훑어볼 수 있는 내용이었다. 전체적인 큰 흐름을 살펴볼 수 있었던 강의
- 이고잉님의 git과 github 특강 매우 유용했다. 특히 이슈 남기는 부분에 label 및 메시지를 받게할 사람을 지정하는 것은 잘 모르고 있었던 기능이었는데 도움이 되었다.
'Boostcamp AI Tech 2th' 카테고리의 다른 글
| [WK02-Day010][21.08.13.Fri] Generative Models, 주간 회고 (0) | 2021.08.13 |
|---|---|
| [WK02-Day009][21.08.12.Thu] RNN, Sequential Models Git&Github 특강 (0) | 2021.08.13 |
| [WK02-Day007][21.08.10.Tue] Optimization, 도메인 특강, 1주차 피드백 (0) | 2021.08.10 |
| [WK02-Day006][21.08.09.Mon] 가독성을 고려한 시각화 (0) | 2021.08.09 |
| [WK01-Day 005][21.08.06.Fri.] 주간 학습 내용 정리 (0) | 2021.08.07 |
Comments