
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- huggingface
- KLUE
- FSML
- beam search
- Conversation System
- BLEU Score
- layer normalization
- Dialogue System
- BELU
- boj
- bert
- fine-tuning
- BoostCamp
- text classification
- Chatbot
- multi-head attention
- MT-DNN
- GPT-1
- ai-tech
- 취업
- pytorch
- Eliza
- Transformer
- scaled dot-product attention
- Prompt Tuning with Rules for Text Classification
- KLUE-RE
- Relation Extraction
- 백준
- NLP
- Transformers
- Today
- Total
dukim's blog
[WK02-Day006][21.08.09.Mon] 가독성을 고려한 시각화 본문
Intro
쉬어가는 날인가, 강의 분량이 많다는 점을 제외하고는 할만했던 날이었다.
강의 복습 내용
[Data Viz 00] 기본 사용법
- 학습 하다가 새롭게 알게된 코드에 대해서 간략한 경우만 남겼고, 구체적인 코드는 남기지 않았습니다.
- 시각화 차트는 스니펫처럼 필요한 차트 있을 때마다 가져다 쓰면서 구조 파악하는 방식으로 학습하는 것이 효율적
- 하지만 강의 때 다룬 디자인 원칙은 상당히 유용하여 짤막하게 정리
조각 코드
- ipynb에서 plot 해상도 높이기
%config InlineBackend.figure_format='retina'
Figure & Axes
import matplotlib.pyplot as plt: matplotlib에 포함된 plt 모듈을 불러와 사용Figure : plot의 큰 틀, Sub plot을 최소 1개 이상 추가해야함
Ax : Sub plot
기본적인 fig 객체 생성 및 sub plot 추가
fig = plt.figure() as = fig.add_subplot() plt.show() # CLI 환경에서 출력시 활용, ipython에서는 실행하지 않아도 출력은 되나 그 떄는 제일 마지막 결과만 출력되기에 작성함
figure 객체의
figsize파라미터는 inch 기준으로 width, height를 나타냄, 노트북 환경에선 비율이 조절되서 나타남
figure 객체에
set_facecolor메서드로 색상설정. figure 객체 속 흰 부분이 sub plotfig = plt.figure(figsize=(12, 7)) fig.set_facecolor('black') ax = fig.add_subplot() plt.show()
figure 객체에 sub plot 추가:
add_subplot(y축 칸 개수, x축 칸 개수, 해당 sub plot의 번호)fig = plt.figure() # ax = fig.add_subplot(121) # ax = fig.add_subplot(1, 2, 1)로 사용가능 ax = fig.add_subplot(122) plt.show()
그래프 그리기
- matplotlib은 두 가지 API를 각각 지원
- Pyplot API : 순차적 방법. 자주 사용되는 단순한 방법으로, 호출 순서에 따라 해당 번호의 sub plot에 그려짐
- 객체지향(Object-Oriented) API : 각각의 subplot 객체를 직접 수정하는 방법, 커스텀이 편리
- 두 API는 거의 비슷한 메서드를 사용하지만, 일부 호환되지 않는 것들이 있음.
- plt로 그린 객체를 ax 객체처럼 사용할 경우 :
plt.gct().get_axes()
- plt로 그린 객체를 ax 객체처럼 사용할 경우 :
한 서브 플롯에서 여러 개 그리기
- 같은 그래프를 여러 개 그리면 다른 색상 배정
- 다른 그래프를 여러 개 그리면 같은 색상 배정
sub plot을 나타내는 ax 객체에서 특정 데이터 변경 또는 값 받아오기
{ax 객체}.set_{설정할 요소}(지정값){ax 객체}.get_{가져올 요소}(): 이미 seaborn 등 다른 라이브러리로 만들어진 객체에서 정보를 가져올 때 사용예시
fig = plt.figure() ax = fig.add_subplot(111) ax.plot([1, 2, 1], label='1') ax.plot([2, 1, 2], label='2') # ax.plot([3, 3, 3], label='3') ax.set_title('Cross Plot') ax.legend() print(ax.get_title()) plt.show()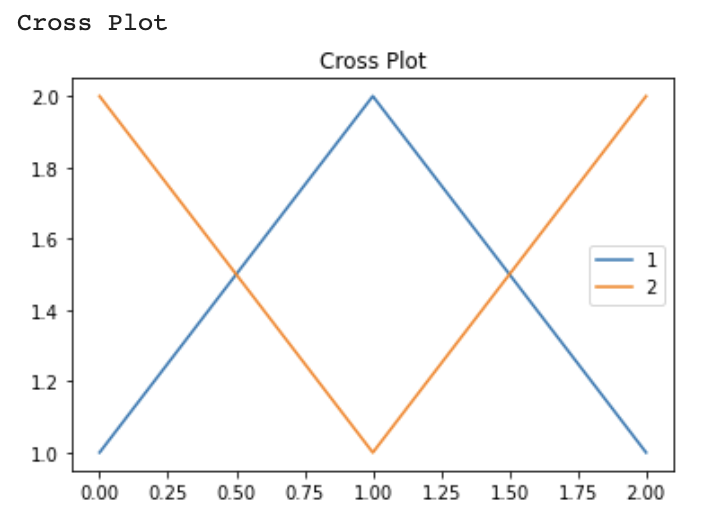
여러 서브플롯에서 적용한 예시
{figure 객체}.suptitle({지정값}): super titlefig = plt.figure() ax1 = fig.add_subplot(121) ax2 = fig.add_subplot(122) ax1.plot([1, 2, 3],[1, 2, 3], label='1') ax1.bar([1, 2, 3],[1, 2, 3], label='2') ax2.plot([1, 2, 1], label='1') ax2.plot([2, 1, 2], label='2') ax1.set_title('[Ax1 Title]: Basic Plot') ax2.set_title('[Ax2 Title]: Basic Plot') ax1.legend() ax2.legend() print(ax1.get_title()) print(ax2.get_title()) fig.suptitle('[Figure Title]: Super Title') # super title plt.show()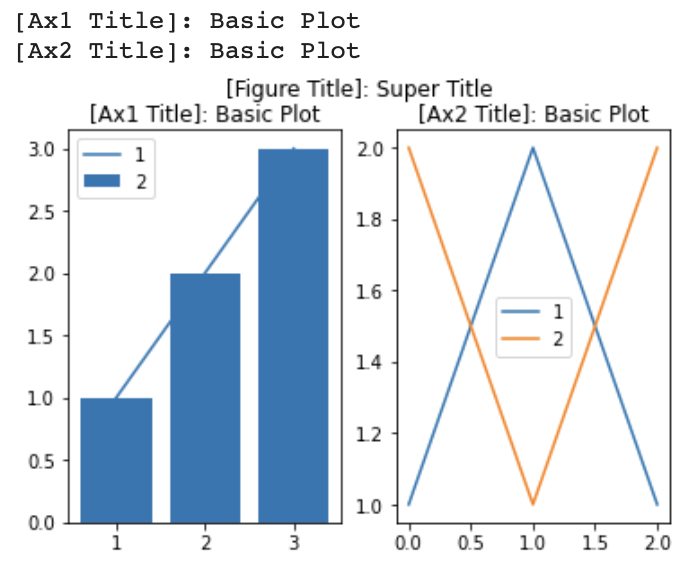
축 정보: ticks, ticklabels
ticks: 축이 적히는 좌표 위치ticklabels: 축에 적힐 텍스트굳이 보여주지 않아도 되는 축의 좌표값을 조절할 때 사용
fig = plt.figure() ax1 = fig.add_subplot(121) ax2 = fig.add_subplot(122) ax1.plot([1, 1, 1], label='1') ax1.plot([2, 2, 2], label='2') ax1.plot([3, 3, 3], label='3') ax2.plot([1, 1, 1], label='1') ax2.plot([2, 2, 2], label='2') ax2.plot([3, 3, 3], label='3') ax1.set_title('no ticks') ax2.set_title('set ticks') ax1.legend() ax2.legend() ax2.set_xticks([0, 1, 2]) ax2.set_xticklabels(['zero', 'one', 'two']) fig.suptitle('Tick Set up') # super title plt.show()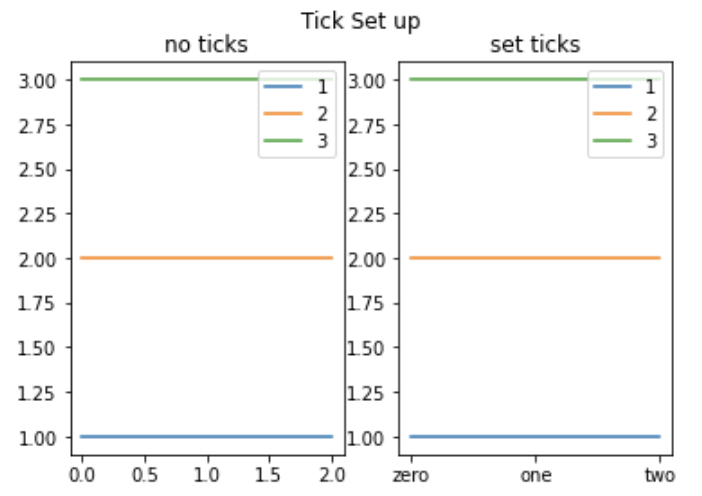
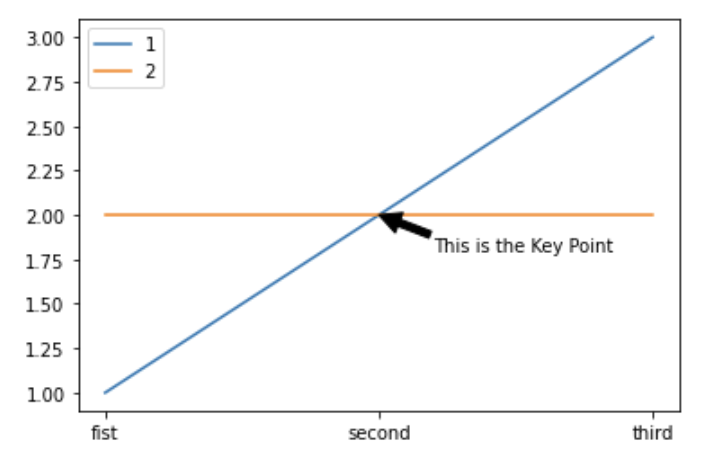
문자열 추가시
다음 두 가지 방법
{ax 객체}.text(x={x 좌표 : int, float}, y={y 좌표 : int, float}, s={입력값 : str}){ax 객체}.annotate(xy={x, y좌표 : tuple}, s={입력값})
두 방식의 차이점: annotate는 설명을 위한 포인트를 지정해주는 것, 따라서 화살표를 지정해 줄 수 있다.
fig = plt.figure() ax = fig.add_subplot(111) ax.plot([1, 2, 3], label='1') ax.plot([2, 2, 2], label='2') ax.set_xticks([0, 1, 2]) ax.set_xticklabels(['fist', 'second', 'third']) ax.annotate(s='This is the Key Point', xy=(1, 2), xytext=(1.2, 1.8), arrowprops=dict(facecolor='black')) ax.legend() plt.show()
[Data Viz 02] Bar Plot
Bar Plot 생성
fig와 subplot 동시에 생성
barh: horizonatl bar plot 생성fig, axes = plt.subplots(1, 2, figsize=(12, 7)) x = list('ABCDE') y = np.array([1, 2, 3, 4, 5]) axes[0].bar(x, y) axes[1].barh(x, y) plt.show()pandas DataFrame 확인 시
sample메서드pandas datafram 확인시
sample({샘플 개수})메서드를 사용하면 무작위로 샘플 추출
다양한 Bar Plot, 어떤 것을 언제 적용할 것인가?
Bar Plot은 1개의 범주형 feature를 보여줌
여러 Group에 대해 보여줄 경우 다음 방식을 고려할 수 있다
플롯을 여러 개 나열
각각의 분포를 파악하기에 좋다. 하지만 비교하기에 어려움
barplot을 여러 서브 플롯으로 만들 때, y축의 범위 통일하기
# 1. subplots의 파라미터 sharey 이용 fig, axes = plt.subplots(1, 2, figsize=(15, 7), sharey=True) # 2. 반복문을 사용한 조절 for ax in axes: ax.set_ylim(0, 200)
한 개의 플롯에 동시에 표현
2.1. Stacked Bar Plot- 맨 밑의 그룹의 분포는 파악하기 쉽지만, 쌓아 올려진 그룹의 분포는 파악하기 어렵다.
- .bar(): bottom 파라미터
- .barh(): left 파라미터
- Persentage Stacked Bar Chart: 상대적인 비율 표현시
- 예시
''' 아래와 같은 데이터가 Hirachical Index를 가진 Series 객체가 group 변수에 주어졌을때 gender race/ethnicity female group A 36 group B 104 group C 180 group D 129 group E 69 male group A 53 group B 86 group C 139 group D 133 group E 71 Name: race/ethnicity, dtype: int64 ''' # bar() : bottom 파라미터에 간격값 입력 ax.bar(group['female'].index, group['female'], bottom=group['male'], color='tomato') # barh() : left 파라미터에 간격값 입력 ax.barh(group['female'].index, group['female'], left=group['male']/total, color='tomato')```
2.2. Overlapped Bar Plot
- 2개 그룹만 비교할 때 좋은 선택지
- 채도에 따라 alpha값을 적절히 조절해 활용
2.3. Grouped Bar Plot
- 범주에 따른 bar를 이웃되게 배치
- matplotlib을 이용한 구현이 까다로움, seaborn을 쓰면 보다 편리
- 5~7개 이하 그룹(magic number 7?)일 때 효과적, 넘어갈 경우 ETC 처리
Bar Plot 정확하게 사용하기
Principle of Proportion Ink
- 실제 값과 이를 표현하는 그래픽 요소의 양은 비례해야 한다는 원칙
- 차이를 강조할 때 y축의 시작값을 바꾸어 표현할 수도 있지만(사회조사쪽 통계에선 이렇게 하라고 배웠었는데...), 실제 값을 오해할 수 있으므로 대신에 세로 비율을 늘려 표현할 것
데이터 정렬:
- 데이터 종류(시계열, 수치형, 순서형, 명목형)에 따라 정렬해 제시 핵심 원칙은 가독성
- 여러 기준으로 정렬하는 과정에서 인사이트를 발견할 수도 있다
- 대시 보드 형태로 제공하는 것도 유용함
여백 조절
- 가독성을 높이기 위한 팁
- X/Y 축 범위 조절(
.set_xlim(),..) - subplot의 spines 제거(
.spines[spine].set_visible())(sub plot의 사각형 태두리를 의미, 답답해 보이지 않기 위해 ticks가 없는 상단과 우측을 제거하기도 함) - barplot의 너비(
width) 조절을 통한 bar 사이의 gap 조절 - legend의 크기와 위치(
.legend()) - Margines(
.margins())(ubplot의 내부 요소와 spines 사이의 간격을 말함, 기본값은 0.05로 빡빡한 편)
복잡함과 단순함
- 단순화: 되도록 2D 지향, 3D를 할거면 interactive하게 제공할 것
- 자료를 읽는 대상 고려: 정확한 차이를 보여줄 것인가, 큰 틀에서의 경향성을 보여줄 것인가
- 축과 디테일의 복잡함: 대상과 관련된 내용, 세밀한 값 차이를 비교하게 하려면 grid를 추가한다던지, 관심있는 요소가 무엇인지에 따라 ticklabels 또는 text를 추가
ETC
- 오차 막대의 표현:
bar()메서드의yerr인자에 std값 추가
- 오차 막대의 표현:
[Data Viz 03] Line Plot
개괄
- 언제쓰는지: 연속적인 변화량의 표현(e.g. 시계열 자료)
- 5개 이하 선 사용 추천
Line Plot을 위한 전처리
- 시계열 데이터는 Noise로 인해 패턴 및 추세 파악이 어려움 따라서 Smoothing 사용(
rolling(window={윈도우 크기}).mean())
# facebook : index가 Datatime인 pd.DataFrame 객체, window size 4 인 이동평균값이 각 column에 계산됨
facebook_rolling_window4 = facebook.rolling(window=4).mean()Line Plot 정확하게 사용하기
- 개괄
- Bar Plot과 달리 추세를 보는 것이 목적, 따라서 min, max에 살짝 마진을 줘서 데이터가 존재하는 범위만 표현(
.set_ylim()) - 단순화하여 제시(grid, annotate, marker 등 제거), 디테일한 정보는 표로 제공
- 물론 절대적인 원칙은 아니며, EDA 등 정확한 파악이 필요할 경우엔 디테일한 정보 살려서 표현
- Bar Plot과 달리 추세를 보는 것이 목적, 따라서 min, max에 살짝 마진을 줘서 데이터가 존재하는 범위만 표현(
- 간격
- plot에는 y축 값만 입력해도 표시되긴 하지만, 되도록 x, y 모두 입력할 것
- ticks간의 간격을 균등하게 맞출 것
- ticks엔 있지만 실제로는 없는 값(그러나 line plot에는 보간되어 표현될 떄)이 혼동을 줄 수 있다. 이땐 marker를 가독성을 떨어트리지 않는 선에서 표기해주는 것이 좋다.
- 이중 축 사용
- 많이 사용하진 않음
twinx()사용하기- sub plot ax 객체의 메서드로, 기존 sub plot ax와 같은 객체이지만 다르게 정의할 수 있는 이중 축이 생김(반대편에)
- 서로 다른 정보(e.g. 종가 & 거래량)를 적을 때 사용한다.
- 가독성이 높지 않기 때문에, 정말 필요할 때 아니면 지양
secondary_xaxis(): https://matplotlib.org/stable/gallery/subplots_axes_and_figures/secondary_axis.html- 같은 정보를 다른 단위로 표현할 때 사용(e.g. sin graph의 각 단위를 radian, degree 둘 다로 표현)
- 많이 사용하진 않음
[Data Viz 04] Scatter Plot
개괄
- 2차원 데이터 표현 또는 두 feature간의 관계 파악에 사용
- n차원 확장시, 색상, 마커의 모양, 크기 등의 요소를 추가하여 표현가능
.scatter()
목적
- 두 feature의 상관관계
- 2차원 feature로 표현되는 데이터 포인트들의 분포 확인
- 군집
- 값 사이의 차이
- 이상치
Scatter Plot 정확하게 사용하기
Overplotting
- 점이 많아질수록 파악이 힘들다. 이를 완화할 수 있는 방법
- 투명도 조정
- jittering :
- 2차원 히스토그램 : heatmap 이용 구간별 빈도 표현
- Contour plot : 분포를 등고선으로 표현
점의 요소와 인지
- visual popout을 고려, 색, 마커의 크기, 모양 순으로 인지가 잘 된다.
- 색: 연속값은 gradient, 이산은 개별 색상
- 크기: 버블 차트(bubble chart), 단 원의 크기 비교가 실제에 비례하지 않음. 각 점간의 상대적 비율만 표현, 범주형 데이터 표현에 추천
- 마커: 가장 구별하기 힘들며, 마커의 모양이 크기에 영향을 줌
인과관계와 상과관계가 다름을 주의
- 인과관계는 항상 사전 정보와 함꼐 가정으로 제시
추세선
- scatter의 패턴 유추, 가독성을 위해 단 1개의 그룹에 대해 전체적인 분포를 살필때만
ETC
- 가독성 위해 Grid 지양, 쓴다면 무채색, 투명도 높일 것
- 범주형 포함된 관계에선 heatmap, bubble chart
조각코드
sub plot 생성시
add_subplot의aspect=1: 가로축과 세로축의 스케일을 동일하게 설정fig = plt.figure(figsize=(7, 7)) ax = fig.add_subplot(111, aspect=1) ...sub plot에 vertical, horizontal line 추가하기
ax.axvline(2.5, color='gray', linestyle=':') ax.axhline(0.8, color='gray', linestyle=':')
[Deep Learning Basic 01]
피어세션
- 모더레이터 : 박준수
- 회의록 : 추창한
- 발표 : 나요한, 김대웅
- Corss Entropy와 KL-Divergence : 요한
- Entropy 설명 추가 : 대웅
- 알고리즘 스터디
- 한준님 문제 강의 요청
- 기타 자유 대화
- 대학원 진학에 대한 고민 상담 및 정보 공유
- 시각화 강의가 너무 많다
- 선택과제 난이도가 너무 어려워 보인다.
- 강의에 자막 있었으면 좋겠다(모바일로 가능?)
- 구글 부트캠프와 비교 등
- Transformer 구현시 도움될 자료 공유(대웅):
학습회고
- 시각화 강의를 빠르게 스킵했어야하나 싶다. 코드 자체는 갤러리에서 복붙해서 쓰면되는데, 다만 가독성을 고려한 시각화를 위한 팁들은 도움이 되었다.
'Boostcamp AI Tech 2th' 카테고리의 다른 글
| [WK02-Day008][21.08.11.Wed] CNN (0) | 2021.08.11 |
|---|---|
| [WK02-Day007][21.08.10.Tue] Optimization, 도메인 특강, 1주차 피드백 (0) | 2021.08.10 |
| [WK01-Day 005][21.08.06.Fri.] 주간 학습 내용 정리 (0) | 2021.08.07 |
| [WK01-Day 004][21.08.05.Thu.] 선택과제, 첫 멘토링, 온보딩 키트 도착 (0) | 2021.08.06 |
| [WK01-Day 003][21.08.04.Wed.] 다시 보는 MLE (0) | 2021.08.06 |