
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 백준
- Transformer
- pytorch
- multi-head attention
- layer normalization
- BoostCamp
- text classification
- Relation Extraction
- Transformers
- KLUE-RE
- Dialogue System
- ai-tech
- BLEU Score
- GPT-1
- Prompt Tuning with Rules for Text Classification
- NLP
- FSML
- bert
- boj
- fine-tuning
- huggingface
- MT-DNN
- Chatbot
- KLUE
- Eliza
- Conversation System
- 취업
- beam search
- scaled dot-product attention
- BELU
- Today
- Total
dukim's blog
ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision 본문
ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
eliza.dukim 2021. 6. 7. 04:24ALIGN: A Large-scale ImaGe and Noisy-Text Embedding
0. Intro
ICML 2021에 accept된 Google AI의 논문 "Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision"는 양질의 visual-language representations을 얻기 위한 연구입니다. 다시 말해, 서로 다른 종류(modality)의 데이터에 대해 통합된 representations을 얻는 것으로, 얻어진 representations은 text-image retrieval, image-text retrieval 등의 task에 활용될 수 있습니다. 예전에도 이러한 연구들이 있어왔지만, 이 연구가 특별한 이유는 학습한 데이터셋의 규모에 있는 듯 합니다. 방법론의 이름인 "ALIGN: A Large-scale ImaGe and Noisy-Text Embedding"에서 짐작할 수 있듯이, 간소화된 preprocessing을 통해 noisy하지만 엄청난 규모의 데이터셋을 구축하여 CLIP을 제치고 Flicker 30K, MSCOCO datset의 retrieval task에서 SotA를 달성했습니다.
논문에서 제시하는 정성적인 결과를 보면 신기할 따름입니다. Figure 4는 ALIGN을 통해 얻은 Visual-Language representation으로 text-image retrieval를 수행한 결과를 보여주고 있는데요, 상단의 query, "Van Gogh Stary Night" 에 뒤따르는 들어가는 단어에 따라 적절한 image가 검색되어 "details"의 경우엔 세밀한 부분의 image가, "in black and white"는 흑백의 image가 검색됩니다. Text 만을 이용한 retrieval 뿐만 아니라 image와 text를 함께 이용한 image retrieval도 가능합니다. Figure 5는 image embedding에서 특정 의미를 나타내는 text embedding을 더하거나 뺀 embedding으로 가장 유사도가 높은 image를 검색한 결과를 제시합니다. 붉은 장미 image의 embedding에 "blue"라는 text embedding을 더한 것과 가장 유사한 이미지로 푸른 장미의 이미지가 검색됩니다.


해당 논문의 이해를 돕기위한 자료를 찾던 중 좋은 자료를 발견하여 공유드리려 합니다. 아래 내용은 Stanord University의 Electronical Engineering 박사과정 Nandita Bhaskhar이 Stanford Contrastive & SS Learning Group에서 지난 2월 26일 발표한 영상의 내용입니다. 논문의 컨셉을 이해하기에 좋은 자료인 것 같아 해당 그룹의 허락을 구하여 번역한 것임을 밝힙니다.
(참고: 본문에 제시된 figure 및 table의 번호는 논문의 번호를 따릅니다)
Contents
1. What? Why? How?
2. Dataset Curation
3. Framework
4. Evaluation
5. Results
6. Ablation Study
7. ALIGN vs CLIP
1. What? Why? How?
What?
- Visual & Visual-Language 에 대한 pre-trianed representation을 학습하는 모델
- Textual(natural langauge)의 supervision을 통해 visual representations을 얻는 기존 연구도 존재
Why?
- Vision application은 대개 class label이 존재하는 대규모 데이터셋을 통해 Supervised learning으로 학습 수행
- 하지만 Vision-language application은 Supervised-Learning을 위한 데이터 전처리 과정에 bottle neck이 발생
- ex) Cleaning, balancing, human annotation, semantic parsing, etc.
- 본 연구에서는 전처리 과정을 단순화하여 noisy한 데이터를 얻는 대신 대규모 데이터(18억개의 이미지-텍스트 쌍)를 통해 전처리 과정이 복잡한 모델(CLIP)과 동일하거나 더 나은 결과를 얻음
How?
- Large-scale data: 10억개의 image-text 쌍
- Noisy: 매우 단순한 data preparing/cleaning 절차
- Shared latent embeddings: contrastive loss를 사용한 dual-encoder 구조
- 이미지에 대한 텍스트쌍은 이미지의 fine-grained labels의 역할
- 기존의 label 기반 classification과 비슷하지만 text-encoder에서 'label'의 역할을 하는 weights를 생성한다는 점이 다르다.
2. Dataset Curation
- Conceptual Caption Dataset의 양식을 따름
- Web 이미지와 이에 딸린 alt-text 쌍을 수집
- 이미지와 텍스트에 대해 단순한 필터링 기법과 전처리를 적용하여 noisy 하지만 18억 쌍의 데이터를 수집
Image-based Filtering
- 부적절하거나 제한적인 이미지 제거
- aspect ratio < 3 이고, 짧은 쪽 차원 > 200px 인 이미지만 선택
- alt-text가 1,000 글자 이상인 이미지 제거
- downstream tasks의 test images와 중복된 이미지 제거
Text-based Filtering
- 10개 이상의 이미지에서 공통적으로 등장하는 alt-text 제거
- 이미지와 무관한 설명인 경우가 많음 : e.g. "1920x1090" or "alt_img"
- 드물게 등장하는 토큰으로 이뤄진 alt-text 제거
- i.e., raw data에 대하여 1억개 이하의 빈도로 등장하는 토큰이 포함된 alt-text 제거
- 길이가 너무 짧거나(< 3 unigrams) 너무 긴 경우( > 20 unigrams) 제거
3. Framework
Architecture
- 의료 이미지 진단에 사용되었던 Dual-encoder architecture(ConVIRT) 사용

- Image Encoder: EfficientNet-L2 with global pooling
- Resize input to 346 x 346
- Final resolution: 289 x 289
- Training: Random crop + horizontal flip
- Evaluation: Central crop
- Text Encoder: BERT-Large with [CLS] token embedding + FC layer
- Wordpiece token으로 최대 64 tokens
Loss Fuction
- ConVIRT와 동일
- Cosine-similarity contrastive training loss
- Contrastive representations을 위한 softmax
- 서로 다른 modality에 대하여 분자엔 positive sample과의 cosine similarity, 분모엔 negative sample과의 cosine similarity의 총합이 위치함
- $x_i$와 $y_j$ : 각각 $i$번째 쌍의 이미지, $j$번째 쌍의 텍스트의 normalized embedding
- $N$ : batch size
- $\sigma$ : temperature to scale the logits
- 최종 loss는 image-to-text, text-to-image 각각의 loss의 합

- Batching:
- Positive: 일치하는 이미지-텍스트 쌍
- Negative: 일치하는 쌍을 제외한 다른 모든 random한 이미지-텍스트 쌍
- Negative는 noisy한 데이터가 될 수 있지만 dataset의 거대한 scale이 noisy를 덜어준다.
- 더 큰 batch를 구성하기 위해 모든 컴퓨팅 코어로부터 embeddings을 concatenate함
- i.e. 1024개 TPU v3 cores에서 각 코어당 16개의 positive sample을 가져옴 -> 효과적인 배치사이즈 1024*16=16384
4. Evaluation
Image-Text Tasks: Flicker30K, MSCOCO
- Downstream tasks(Retrieval):
- Image-to-text
- text-to-image
- fine-tuning을 한 조건과 하지 않은 조건(zero-shot) 모두 실험
Crisscrossed Captions (CxC)
- MS-COCO 데이터셋의 확장판, 267,095개의 intra- and inter-modality 쌍에 대하여 인간이 판단한 semantic similarity 점수로 구성
- Downstream tasks(Retrieval):
- image-to-text
- text-to-image
- image-to-image
- text-to-text
- Downstream tasks(Similarity):
- Semantic Textual Similarity (STS)
- Semantic Image Similarity (SIS)
- Semantic Image-Text Similarity (SITS)
Image Classification Tasks
- Downstream tasks:
- ImageNet ILSVRC-2012 Benchmark
- Frozen ALIGN encoder + fine-tune classification layer
- Fully fine-tuned
- Oxford Flowers-102
- Oxford-IIIT Pets
- Stanford Cars
- Food 101
- Visual Task Adaptation Benchmark
- ImageNet ILSVRC-2012 Benchmark
5. Results
Image-text tasks
- intra-modal, inter-modal retrieval tasks 모두에서 zero-shot과 fine-tuned 조건 모두에서 SotA 달성
- CLIP 대비 근소한 차이로 더 좋은 성능을 보임


- 평가지표: Recall @ K, K = 1, 5, 10 [top-K retrievals 중 query의 ground truth가 존재하는 경우의 비율]
- 주목할만한 점: ALIGN은 intra-modal tasks에서 눈에 띌만한 성능을 내진 못함(text-text / image-image / STS / SIS)

Table 3. Spearman's R Bootstrap Correlation(x100) on Criss-crossed Captions (CxC) dataset(Jia et al. 2021). - text-text / image-image retrieval task의 경우 image-text, text-image에 비해 성능 향상폭이 크지 않음(table 2)
- 저자들은 ALIGN의 training objective가 intra-modal matching 대신 cross-modal matching에 중점을 두고 있기 때문이라 추측.
- Parekh et al. (2021)은 Multi-task setting(cross-modal, and intra-modal)으로 학습시 두 태스크에 대해 보다 균형잡힌 representations을 얻음을 제시함.
Image-only tasks
- 몇몇 벤치마크에 대해서만 더 뛰어난 성능을 보임

6. Ablation Study
Model Architecture Size: Bigger is better
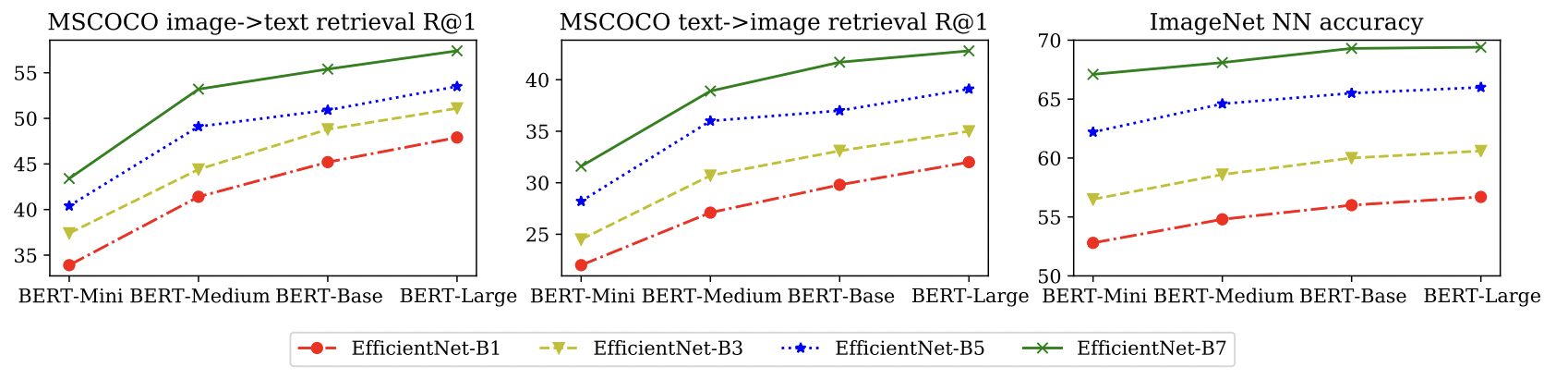
Training Data Size: A lot is better

7. ALIGN vs CLIP
CLIP: Contrastive Language-Image Pretraining
- OpenAI
- image-text modality에 대한 Contrastive learning이라는 점에서 동일
- Encoder Arichtecture의 차이
- Vision encoder: Vision Transformer(ALIGN: EfficientNet-L2)
- Language encoder: GPT family(ALIGN: BERT-Large)
- Training times: 256 GPUs, 2주 (ALIGN: 1024 TPU v3, training time은 나와있지 않음).
- Dataset curation: ALIGN에 비해 복잡함
- English Wikipedia에서 자주 등장하는 visual concepts를 추려내야하기 때문
- ALIGN의 seling points: 데이터셋의 규모가 커질수록 noise를 무시할 수 있게되어 전처리 절차에 드는 비용을 줄일 수 있으며, SotA까지 달성가능
Reference
- Stanford Contrastive & SS Learning Group 발표 영상: ALIGN: Scaling Up Visual and Vision-Language Representation LearningWith Noisy Text Supervision
- Google AI Blog Post: ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
- Jia, Chao, et al. "Scaling up visual and vision-language representation learning with noisy text supervision." arXiv preprint arXiv:2102.05918 (2021).
'NLP' 카테고리의 다른 글
| Large-Scale LM에 대한 얕고 넓은 지식들 (Part 2) (0) | 2021.09.06 |
|---|---|
| Fine-tuning a model on the KLUE-STS (1) | 2021.08.11 |
| Fine-tuning a model on the YNAT (0) | 2021.08.07 |
| Eliza in Python - (2) (0) | 2021.04.03 |
| Eliza in Python - (1) (0) | 2021.04.03 |

